User: All men are mortal. Socrates is a man. What else do we know about Socrates?
ChatGPT: We can conclude that Socrates is mortal.
This looks like reasoning. It isn't. It's picking (based on "attention" to the input prompt, and its trained word-probabilities) the next word to output. So it picks "We can conclude that Socrates is" and at this point it could have completed with "n't mortal", "mortal", "a dog" etc. but "mortal" has the highest score so that's what's picked. It's also kind of a bad example of reasoning because the context (input text by the user/previous replies by the bot) is clearly weighting "is mortal" for "Socrates" very highly when the attention mechanism reads that context.
Regardless, there was no thought process or reasoning happening. Even "chain of thought" and other methods in use for making LLMs "reason better" are basically a trick, because outputting text that describes (the most likely based on weights from training and context) some plausible reasoning process is then attended to and is more likely to produce a weighting that gives a better result.
That said, it can be used "like reasoning" in practice: For automating things that require a little bit of fuzziness, like if you want to ask a question about some text but don't have the exact word to search. It's decent at that.
It fails at planning, hard.
It's also (as of this moment) impossible to get these to actually learn new things dynamically, because the model's weights are fixed after training (training is slow and takes lots of memory). Naive methods of context implementations are quadratic to the number of tokens, so a super long context (needed for long term learning) is currently out of reach, though there are techniques to extend this, but even then we're talking about extending to 1m ish tokens, which will still require hundreds of GBs of very fast RAM (VRAM or similar) and is still inadequate for a long term memory.
What we will see instead is narrow expert models that are good at some task or job and can deal with that specific thing adequately (like automating basic computer tasks like sorting files, drafting boilerplate emails etc.).
The vision enabled ones are useful for recognition tasks etc.
They're going to be very useful and already are in natural language tasks, but "AGI" this is not.
Another example from my own tinkering is something I've wanted for a while which was not really achievable with previous NLP machine learning or heuristic systems, which is pulling out key information from a conversation and formatting it into a machine readable format (granted formatting it isn't great unless you use other techniques but those do exist).
For my case, I want to generate some dialogue from a character using a certain LLM that's good at that, have another LLM look at the generated dialogue of the NPC and tell the game certain things:
Was a quest/task offered?
Were enemies mentioned? And if so, what types? From those types and the types of enemies actually in my game, which ones should I spawn?
What locations were mentioned in relation to the task?
All of these things were technically possible not using LLMs with very cumbersome and hard to utilize NLP libraries that can manually break down written English text into Subject-Object-Verb or other similar structured data, but getting at the actually interesting data was much more difficult and brittle - if your code that looked at the returned extracted language modeling didn't account for something, or if the text was poorly written grammatically etc, it could easily (and usually did) fail, whereas all of the above are trivial for an LLM to complete mostly-correctly.
Well like I said, tasks, not reasoning or understanding.
Example: I have 10GB of memes broadly separated into folders, but otherwise unorganized - names of files are random. Given a multi-modal LLM - i.e., can "see" (really describe) images - it's quite capable of going through each image and renaming them to a descriptive file name based on the image content, just given a prompt telling it to do that.
Same for some of the UI interaction models, where you can say "Click the button that says 'OK' in this program" and it still works even if the text on the button is "Okay", "Ok" or even "Accept" etc.
Yes you can manually do a lot of those things as well but it's more cumbersome than without LLMs.
Reasoning and "intelligence" isn't actually required for it to be useful for NLP tasks.
I actually am doing a lot of this stuff in my day job, and I can say the ability to do fuzzy type searching, instruction etc is light years ahead of where it was just a couple years ago. Doesn't mean they're intelligent or are "AI", just that they're good at attending the input context in a way that makes generating the right (or at least, usually good enough) response much easier.
Yeah I should say I am not an academic and don't care about academic versions of phrases, so when I say natural language task I just mean something where you are using natural language to describe it or it requires some operation on natural language data (conversations etc etc), not a rigidly formalized specification as you might see in related academic literature.

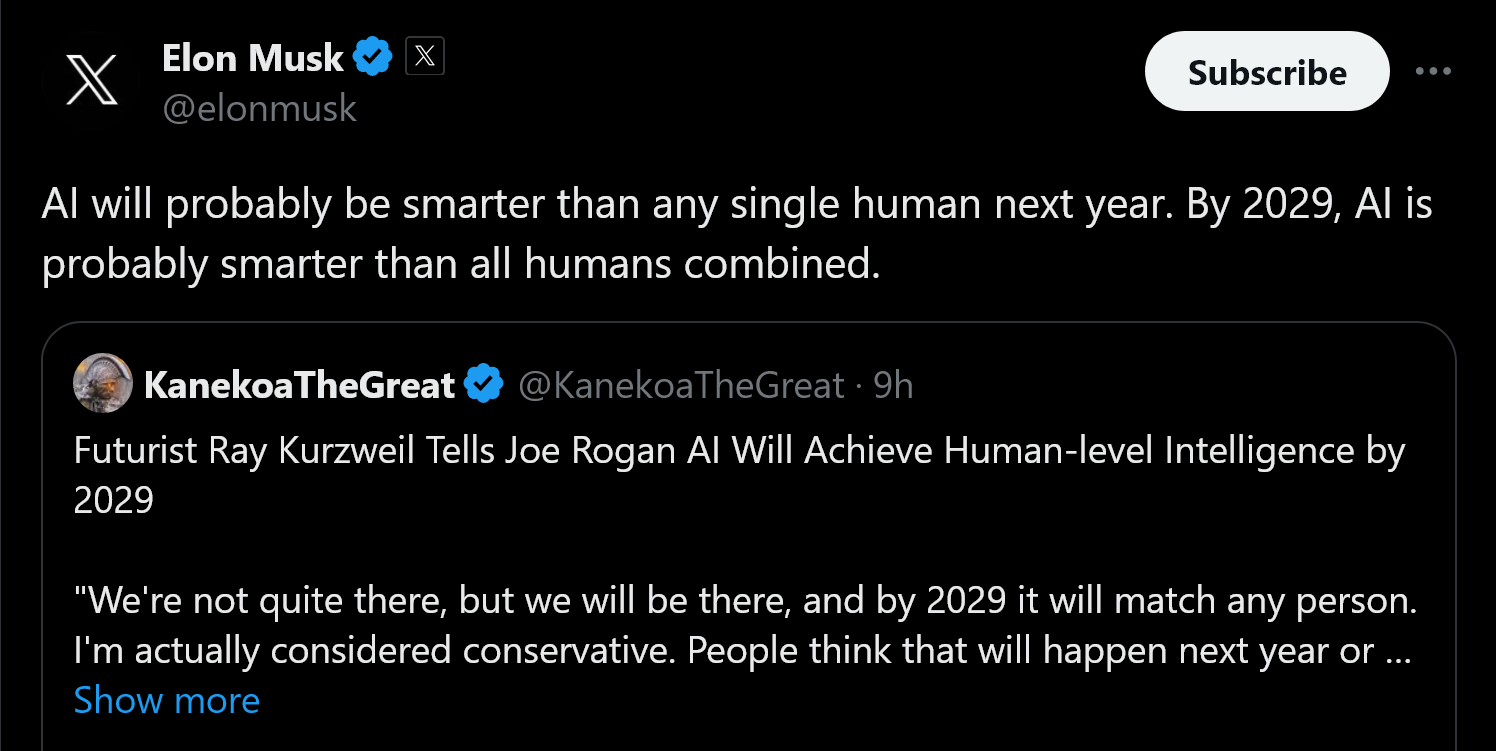
Yep, came to post much the same.
Was reading this: https://github.com/neurallambda/neurallambda yesterday and it has a really good example of what these LLMs actually do:
https://github.com/neurallambda/neurallambda/raw/master/doc/socrates.png
Text for the lazy:
This looks like reasoning. It isn't. It's picking (based on "attention" to the input prompt, and its trained word-probabilities) the next word to output. So it picks "We can conclude that Socrates is" and at this point it could have completed with "n't mortal", "mortal", "a dog" etc. but "mortal" has the highest score so that's what's picked. It's also kind of a bad example of reasoning because the context (input text by the user/previous replies by the bot) is clearly weighting "is mortal" for "Socrates" very highly when the attention mechanism reads that context.
Regardless, there was no thought process or reasoning happening. Even "chain of thought" and other methods in use for making LLMs "reason better" are basically a trick, because outputting text that describes (the most likely based on weights from training and context) some plausible reasoning process is then attended to and is more likely to produce a weighting that gives a better result.
That said, it can be used "like reasoning" in practice: For automating things that require a little bit of fuzziness, like if you want to ask a question about some text but don't have the exact word to search. It's decent at that.
It fails at planning, hard.
It's also (as of this moment) impossible to get these to actually learn new things dynamically, because the model's weights are fixed after training (training is slow and takes lots of memory). Naive methods of context implementations are quadratic to the number of tokens, so a super long context (needed for long term learning) is currently out of reach, though there are techniques to extend this, but even then we're talking about extending to 1m ish tokens, which will still require hundreds of GBs of very fast RAM (VRAM or similar) and is still inadequate for a long term memory.
What we will see instead is narrow expert models that are good at some task or job and can deal with that specific thing adequately (like automating basic computer tasks like sorting files, drafting boilerplate emails etc.).
The vision enabled ones are useful for recognition tasks etc.
They're going to be very useful and already are in natural language tasks, but "AGI" this is not.
Another example from my own tinkering is something I've wanted for a while which was not really achievable with previous NLP machine learning or heuristic systems, which is pulling out key information from a conversation and formatting it into a machine readable format (granted formatting it isn't great unless you use other techniques but those do exist).
For my case, I want to generate some dialogue from a character using a certain LLM that's good at that, have another LLM look at the generated dialogue of the NPC and tell the game certain things:
All of these things were technically possible not using LLMs with very cumbersome and hard to utilize NLP libraries that can manually break down written English text into Subject-Object-Verb or other similar structured data, but getting at the actually interesting data was much more difficult and brittle - if your code that looked at the returned extracted language modeling didn't account for something, or if the text was poorly written grammatically etc, it could easily (and usually did) fail, whereas all of the above are trivial for an LLM to complete mostly-correctly.
Well like I said, tasks, not reasoning or understanding.
Example: I have 10GB of memes broadly separated into folders, but otherwise unorganized - names of files are random. Given a multi-modal LLM - i.e., can "see" (really describe) images - it's quite capable of going through each image and renaming them to a descriptive file name based on the image content, just given a prompt telling it to do that.
Same for some of the UI interaction models, where you can say "Click the button that says 'OK' in this program" and it still works even if the text on the button is "Okay", "Ok" or even "Accept" etc.
Yes you can manually do a lot of those things as well but it's more cumbersome than without LLMs.
Reasoning and "intelligence" isn't actually required for it to be useful for NLP tasks.
I actually am doing a lot of this stuff in my day job, and I can say the ability to do fuzzy type searching, instruction etc is light years ahead of where it was just a couple years ago. Doesn't mean they're intelligent or are "AI", just that they're good at attending the input context in a way that makes generating the right (or at least, usually good enough) response much easier.
Yeah I should say I am not an academic and don't care about academic versions of phrases, so when I say natural language task I just mean something where you are using natural language to describe it or it requires some operation on natural language data (conversations etc etc), not a rigidly formalized specification as you might see in related academic literature.